Outbreak Detection in Networks
Introduction
The general goal of outbreak detection in networks is that given a dynamic process spreading over a network, we want to select a set of nodes to detect the process efficiently. Outbreak detection in networks has many applications in real life. For example, where should we place sensors to quickly detect contaminations in a water distribution network? Which person should we follow on Twitter to avoid missing important stories?
The following figure shows the different effects of placing sensors at two different locations in a network:
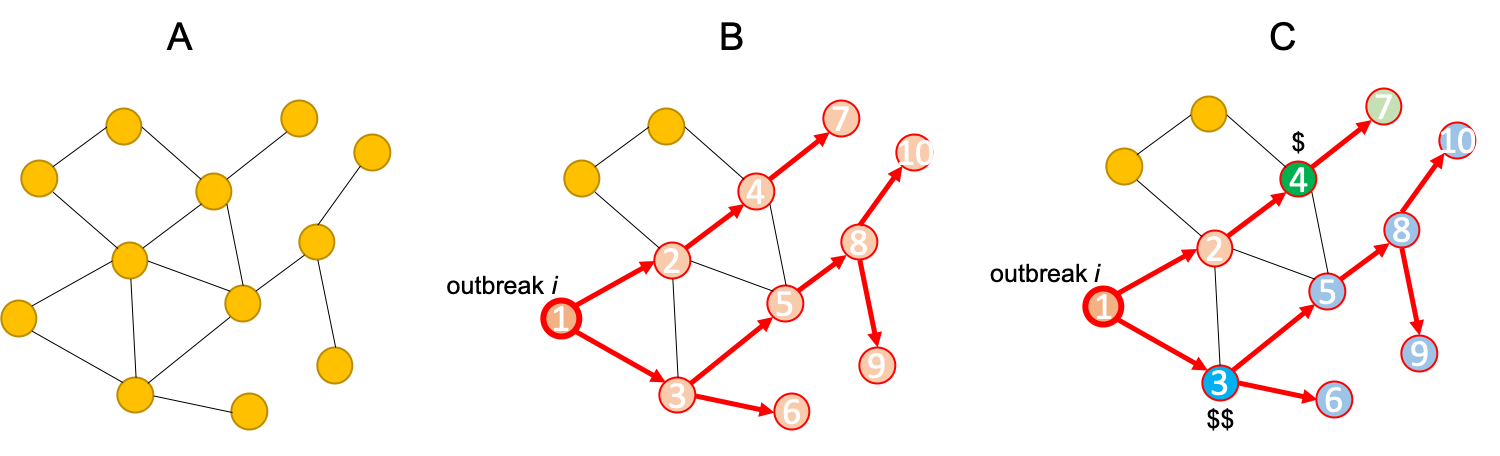 (A) The given network. (B) An outbreak starts and spreads as shown. (C) Placing a sensor at the blue position saves more people and also detects earlier than placing a sensor at the green position, though costs more.
(A) The given network. (B) An outbreak starts and spreads as shown. (C) Placing a sensor at the blue position saves more people and also detects earlier than placing a sensor at the green position, though costs more.
Problem Setup
The outbreak detection problem is defined as below:
- Given: a graph and data on how outbreaks spread over this (for each outbreak , we knew the time when the outbreak contaminates node ).
- Goal: select a subset of nodes that maximize the expected reward:
where
- : probability of outbreak occurring
- : rewarding for detecting outbreak using “sensors” It is obvious that is the expected reward for detecting the outbreak
- : total budget of placing “sensors”
The Reward can be one of the following three:
- Minimize the time to detection
- Maximize the number of detected propagations
- Minimize the number of infected people
The Cost is context-dependent. Examples are:
- Reading big blogs is more time consuming
- Placing a sensor in a remote location is more expensive
Outbreak Detection Formalization
Objective Function for Sensor Placements
Define the penalty for detecting outbreak at time , which can be one of the following:Notice: in all the three cases detecting sooner does not hurt! Formally, this means, for all three cases, is monotonically nondecreasing in .
- Time to Detection (DT)
- How long does it take to detect an outbreak?
- Penalty for detecting at time :
- Detection Likelihood (DL)
- How many outbreaks do we detect?
- Penalty for detecting at time : , this is a binary outcome: means we detect the outbreak and we pay 0 penalty, while means we fail to detect the outbreak and we pay 1 penalty. That is we do not incur any penalty if we detect the outbreak in finite time, otherwise we incur penalty 1.
- Population Affected (PA)
- How many people/nodes get infected during an outbreak?
- Penalty for detecting at time : number of infected nodes in the outbreak by time
The objective reward function of a sensor placement is defined as penalty reduction:
where is the time when the set of “sensors” detects the outbreak .
Claim 1: is monotoneFor the definition of monotone, see Influence Maximization
Firstly, we do not reduce the penalty, if we do not place any sensors. Therefore, and .
Secondly, for all ( is all the nodes in ), , and
Because is monotonically nondecreasing in (see sidenote 2), . Therefore, is nondecreasing. It is obvious that is also nondecreasing, since .
Hence, is monotone.
Claim 2: is submodularFor the definition of submodular, see Influence Maximization
This is to proof for all :
There are three cases when sensor detects the outbreak :
- ( detects late): nobody benefits. That is and . Therefore,
- ( detects after but before ): only helps to improve the solution of but not . Therefore,
- ( detects early): Inequality is due to the nondecreasingness of , i.e. (see Claim 1).
Therefore, is submodular. Because , is also submodular.Fact: a non-negative linear combination of submodular functions is a submodular function.
We know that the Hill Climbing algorithm works for optimizing problems with nondecreasing submodular objectives. However, it does not work well in this problem:
- Hill Climbing only works for the cases that each sensor costs the same. For this problem, each sensor has cost .
- Hill Climbing is also slow: at each iteration, we need to re-evaluate marginal gains of all nodes. The run time is for placing sensors.
Hence, we need a new fast algorithm that can handle cost constraints.
CELF: Algorithm for Optimziating Submodular Functions Under Cost Constraints
Bad Algorithm 1: Hill Climbing that ignores the cost
Algorithm
- Ignore sensor cost
- Repeatedly select sensor with highest marginal gain
- Do this until the budget is exhausted
This can fail arbitrarily bad! Example:
- Given sensors and a budget
- : reward , cost
- ,…, : reward , cost ( is an arbitrary positive small number)
- Hill Climbing always prefers to other cheaper sensors, resulting in an arbitrarily bad solution with reward instead of the optimal solution with reward , when .
Bad Algorithm 2: optimization using benefit-cost ratio
Algorithm
- Greedily pick the sensor that maximizes the benefit to cost ratio until the budget runs out, i.e. always pick
This can fail arbitrarily bad! Example:
- Given 2 sensors and a budget
- : reward , cost
- : reward , cost
- Then the benefit ratios for the first selection are: 2 and 1, respectively
- This algorithm will pick and then cannot afford , resulting in an arbitrarily bad solution with reward instead of the optimal solution , when .
Solution: CELF (Cost-Effective Lazy Forward-selection)
CELF is a two-pass greedy algorithm [Leskovec et al. 2007]:
- Get solution using unit-cost greedy (Bad Algorithm 1)
- Get solution using benefit-cost greedy (Bad Algorithm 2)
- Final solution
Approximation Guarantee
- CELF achieves factor approximation.
CELF also uses a lazy evaluation of (see below) to speedup Hill Climbing.
Lazy Hill Climbing: Speedup Hill Climbing
Intuition
- In Hill Climbing, in round , we have picked sensors. Now, pick
- By submodularity for .
- Let and be the marginal gains. Then, we can use as upper bound on for ()
Lazy Hill Climbing Algorithm:
- Keep an ordered list of marginal benefits from previous iteration
- Re-evaluate only for the top nodes
- Reorder and prune from the top nodes
The following figure show the process.
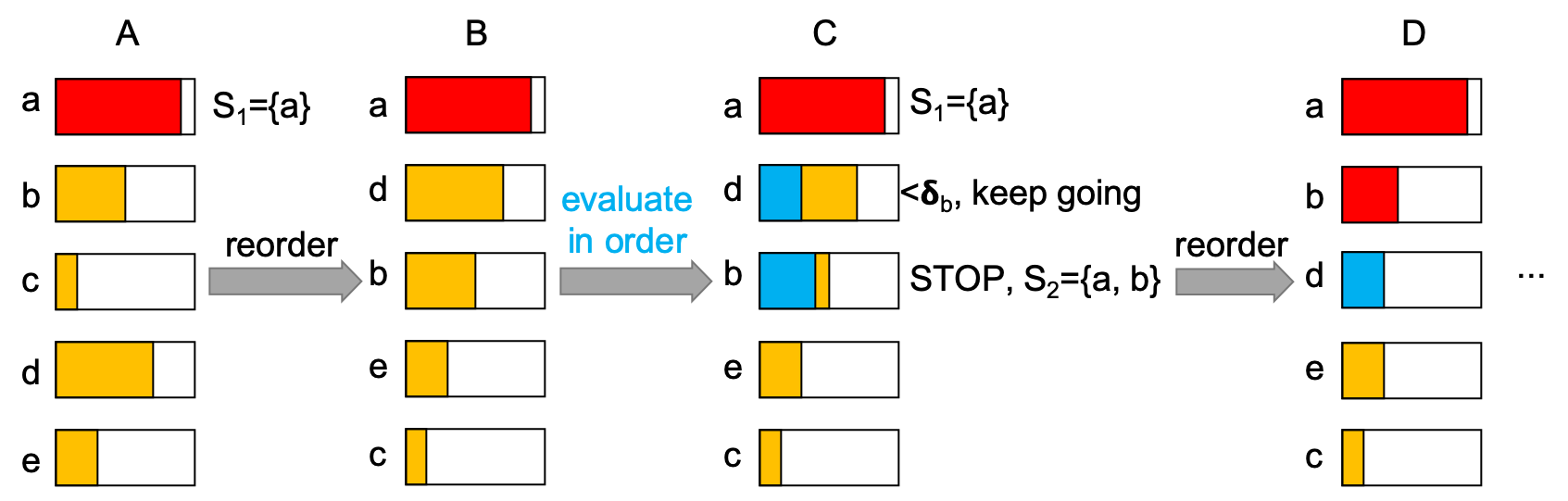
(A) Evaluate and pick the node with the largest marginal gain . (B) reorder the marginal gain for each sensor in decreasing order. (C) Re-evaluate the s in order and pick the possible best one by using previous s as upper bounds. (D) Reorder and repeat.
Note: the worst case of Lazy Hill Climbing has the same time complexity as normal Hill Climbing. However, it is on average much faster in practice.
Data-Dependent Bound on the Solution Quality
Introduction
- Value of the bound depends on the input data
- On “easy data”, Hill Climbing may do better than the bound for submodular functions
Data-Dependent Bound
Suppose is some solution to subjected to , and is monotone and submodular.
- Let be the optimal solution
- For each let
- Order so that
- Then, the data-dependent bound is
Proof:For the first inequality, see the lemma in 3.4.1 of this handout. For the last inequality in the proof: instead of taking of benefit , we take the best possible element , because we do not know .
Note:
- This bound hold for the solution (subjected to ) of any algorithm having the objective function monotone and submodular.
- The bound is data-dependent, and for some inputs it can be very “loose” (worse than )