Influence Maximization
Motivation
Identification of influential nodes in a network has important practical uses. A good example is “viral marketing”, a strategy that uses existing social networks to spread and promote a product. A well-engineered viral marking compaign will identify the most influential customers, convince them to adopt and endorse the product, and then spread the product in the social network like a virus.
The key question is how to find the most influential set of nodes? To answer this question, we will first look at two classical cascade models:
- Linear Threshold Model
- Independent Cascade Model
Then, we will develop a method to find the most influential node set in the Independent Cascade Model.
Linear Threshold Model
In the Linear Threshold Model, we have the following setup:
- A node has a random threshold
- A node influenced by each neighbor according to a weight , such that
- A node becomes active when at least fraction of its neighbors are active. That is
The following figure demonstrates the process:
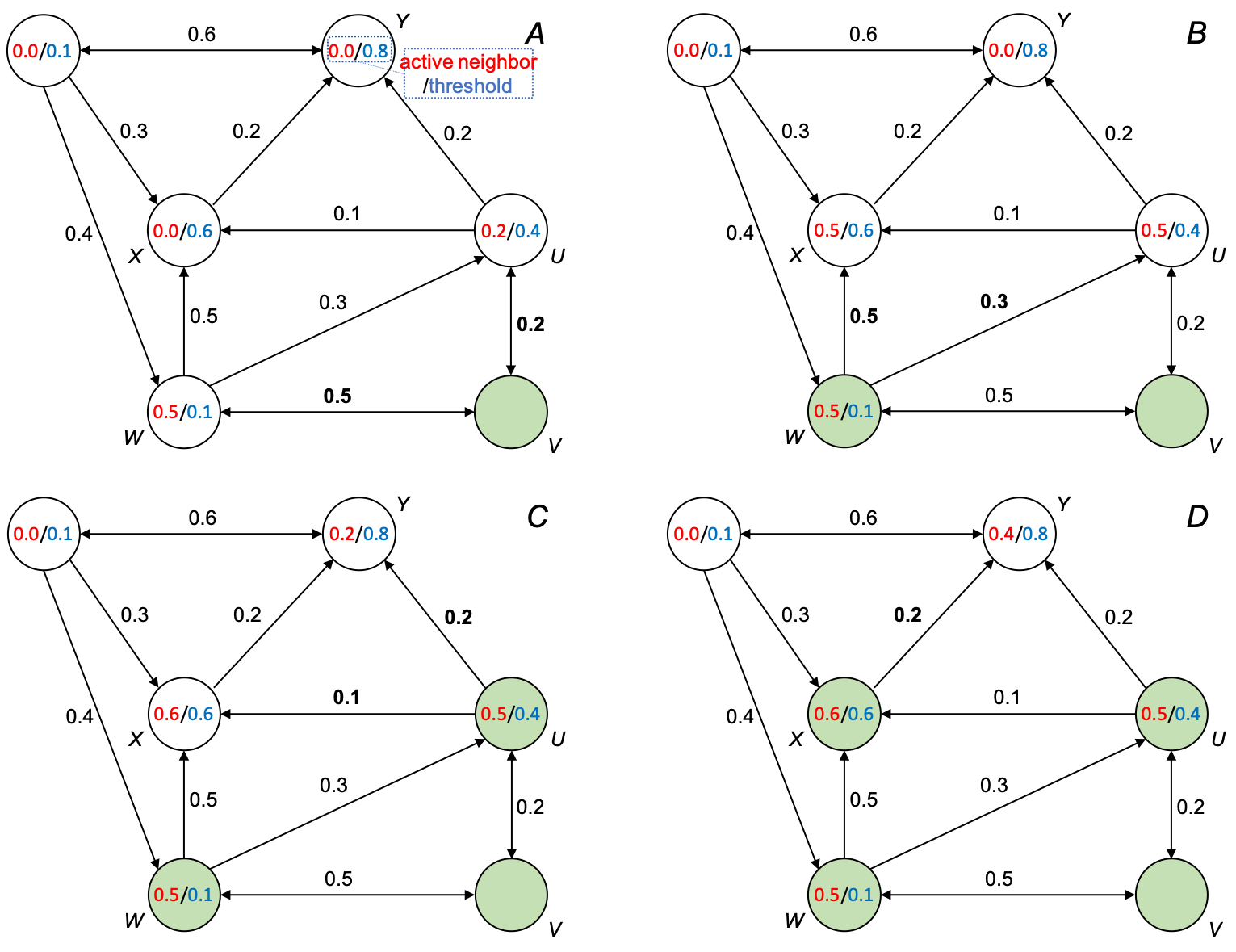
(A) node V is activated and influences W and U by 0.5 and 0.2, respectively; (B) W becomes activated and influences X and U by 0.5 and 0.3, respectively; (C) U becomes activated and influences X and Y by 0.1 and 0.2, respectively; (D) X becomes activated and influences Y by 0.2; no more nodes can be activated; process stops.
Independent Cascade Model
In this model, we model the influences (activation) of nodes based on probabilities in a directed graph:
- Given a directed finite graph
- Given a node set starts with a new behavior (e.g. adopted new product and we say they are active)
- Each edge has a probability
- If node becomes active, it gets one chance to make active with probability
- Activation spread through the network
Note:
- Each edge fires only once
- If and are both active and link to , it does not matter which tries to activate first
Influential Maximization (of the Independent Cascade Model)
Definitions
- Most influential Set of size ( is a user-defined parameter) is a set containing nodes that if activated, produces the largest expectedWhy “expected cascade size”? Due to the stochastic nature of the Independent Cascade Model, node activation is a random process, and therefore, is a random variable. In practice, we would like to compute many random simulations and then obtain the expected value , where is a set of simulations. cascade size .
- Influence set of node is the set of nodes that will be eventually activated by node . An example is shown below.
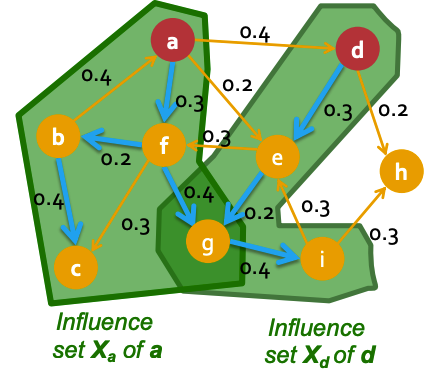
Red-colored nodes a and b are active. The two green areas enclose the nodes activated by a and b respectively, i.e. and .
Note:
- It is clear that is the size of the union of : .
- Set is more influential, if is larger
Problem Setup
The influential maximization problem is then an optimization problem:
This problem is NP-hard [Kempe et al. 2003]. However, there is a greedy approximation algorithm–Hill Climbing that gives a solution with the following approximation guarantee:
where is the globally optimal solution.
Hill Climbing
Algorithm: at each step , activate and pick the node that has the largest marginal gain :
- Start with
- For
- Activate node that
- Let
Claim: Hill Climbing produces a solution that has the approximation guarantee .
Proof of the Approximation Guarantee of Hill Climbing
Definition of Monotone: if and for all , then is monotone.
Definition of Submodular: if for any node and any , then is submodular.
Theorem [Nemhauser et al. 1978]:also see this handout if is monotone and submodular, then the obtained by greedily adding elements that maximize marginal gains satisfies
Given this theorem, we need to prove that the largest expected cascade size function is monotone and submodular.
It is clear that the function is monotone based on the definition of If no nodes are active, then the influence is 0. That is . Because activating more nodes will never hurt the influence, if ., and we only need to prove is submodular.
Fact 1 of Submodular Functions: is submodular, where is a set. Intuitively, the more sets you already have, the less new “area”, a newly added set will provide.
Fact 2 of Submodular Functions: if are submodular and , then is also submodular. That is a non-negative linear combination of submodular functions is a submodular function.
Proof that is Submodular: we run many simulations on graph G (see sidenote 1). For the simulated world , the node has an activation set , then is the size of the cascades of for world . Based on Fact 1, is submodular. The expected influence set size is also submodular, due to Fact 2. QED.
Evaluation of and Approximation Guarantee of Hill Climbing In Practice: how to evaluate is still an open question. The estimation achieved by simulating a number of possible worlds is a good enough evaluation [Kempe et al. 2003]:
- Estimate by repeatedly simulating possible worlds, where is the number of nodes and is a small positive real number
- It achieves -approximation to
- Hill Climbing is now a -approximation
Speed-up Hill Climbing by Sketch-Based Algorithms
Time complexity of Hill Climbing
To find the node that (see the algorithm above):
- we need to evaluate the (the influence set) of each of the remaining nodes which has the size of ( is the number of nodes in )
- for each evaluation, it takes time to flip coins for all the edges involved ( is the number of edges in )
- we also need simulations to estimate the influence set ( is the number of simulations/possible worlds)
We will do this (number of nodes to be selected) times. Therefore, the time complexity of Hill Climbing is , which is slow. We can use sketches [Cohen et al. 2014] to speed up the evaluation of by reducing the evaluation time from to Besides sketches, there are other proposed approaches for efficiently evaluating the influence function: approximation by hypergraphs [Borgs et al. 2012], approximating Riemann sum [Lucier et al. 2015], sparsification of influence networks [Mathioudakis et al. 2011], and heuristics, such as degree discount [Chen et al. 2009]..
Single Reachability Sketches
- Take a possible world (i.e. one simulation of the graph using the Independent Cascade Model)
- Give each node a uniform random number
- Compute the rank of each node , which is the minimum number among the nodes that can reach in this world.
Intuition: if can reach a large number of nodes, then its rank is likely to be small. Hence, the rank of node can be used to estimate the influence of node in .
However, influence estimation based on Single Reachability Sketches (i.e. single simulation of ) is inaccurate. To make a more accurate estimate, we need to build sketches based on many simulationsThis is similar to take an average of in sidenote 1, but in this case, it is achieved by using Combined Reachability Sketches., which leads to the Combined Reachability Sketches.
Combined Reachability Sketches
In Combined Reachability Sketches, we simulate several possible worlds and keep the smallest values among the nodes that can reach in all the possible worlds.
-
Construct Combined Reachability Sketches:
- Generate a number of possible worlds
- For node , assign uniformly distributed random numbers to all pairs, where is the node in ’s reachable nodes set in the world .
- Take the smallest as the Combined Reachability Sketches
-
Run Greedy for Influence Maximization:
- Whenever the greedy algorithm asks for the node with the largest influence, pick node that has the smallest value in its sketch.
- After is chosen, find its influence set , mark the as infected and remove their from the sketches of other nodes.
Note: using Combined Reachability Sketches does not provide an approximation guarantee on the true expected influence but an approximation guarantee with respect to the possible worlds considered.