Graph Neural Networks
In the previous section, we have learned how to represent a graph using “shallow encoders”. Those techniques give us powerful expressions of a graph in a vector space, but there are limitations as well. In this section, we will explore three different approaches using graph neural networks to overcome the limitations.
Limitations of “Shallow Encoders”
- Shallow Encoders do not scale, as each node has a unique embedding.
- Shallow Encoders are inherently transductive. It can only generate embeddings for a single fixed graph.
- Node Features are not taken into consideration.
- Shallow Encoders cannot be generalized to train with different loss functions.
Fortunately, graph neural networks can solve the above limitations.
Graph Convolutional Networks (GCN)
Traditionally, neural networks are designed for fixed-sized graphs. For example, we could consider an image as a grid graph or a piece of text as a line graph. However, most of the graphs in the real world have an arbitrary size and complex topological structure. Therefore, we need to define the computational graph of GCN differently.
Setup
Given a graph such that:
- is the vertex set
- is the adjacency matrix
- is the node feature matrix
Computational Graph and Generalized Convolution
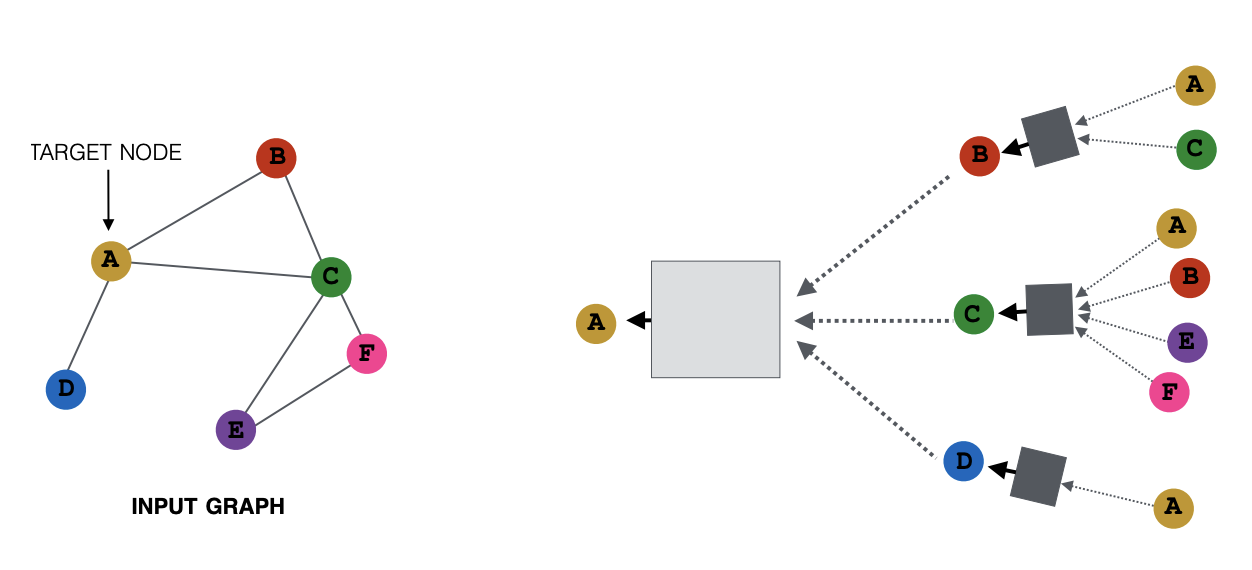
Let the example graph (referring to the above figure on the left) be our . Our goal is to define a computational graph of GCN on . The computational graph should keep the structure of and incorporate the nodes’ neighboring features at the same time. For example, the embedding vector of node should consist of its neighbor , and not depend on the ordering of . One way to do this is to simply take the average of the features of . In general, the aggregation function (referring to the boxes in the above figure on the right) needs to be order invariant (max, average, etc.). The computational graph on with two layers will look like the following:

Here, each node defines a computational graph based on its neighbors. In particular, the computational graph for node can be viewed as the following (Layer-0 is the input layer with node feature ):
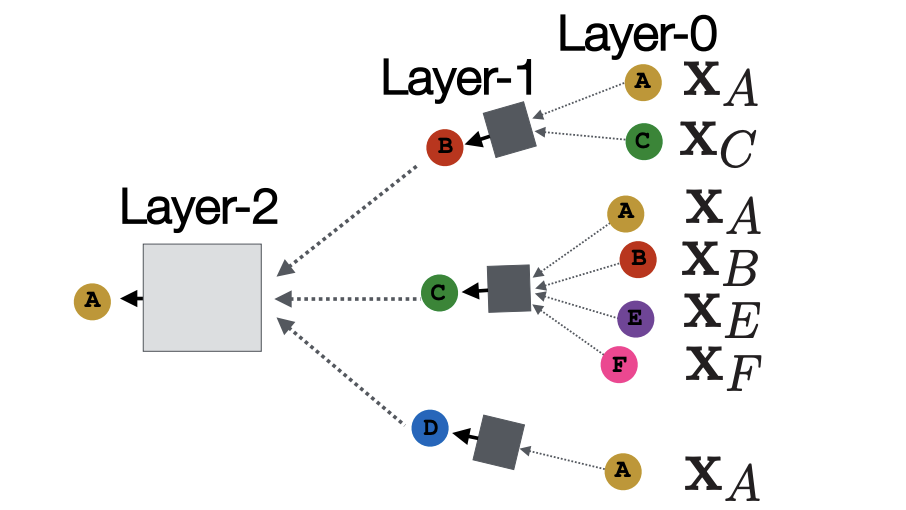
Deep Encoders
With the above idea, here is the mathematical expression at each layer for node using the average aggregation function:
-
At 0th layer: . This is the node feature.
-
At kth layer: .
is the embedding of node from the previous layer. is the number of the neighbors of node . The purpose of is to aggregate neighboring features of from the previous layer. is the activation function (e.g. ReLU) to introduce non-linearity. and are the trainable parameters.
- Output layer: . This is the final embedding after layers.
Equivalently, the above computation can be written in a matrix multiplication form for the entire graph:
such that .
Training the Model
We can feed these embeddings into any loss function and run stochastic gradient descent to train the parameters. For example, for a binary classification task, we can define the loss function as:
is the node class label. is the encoder output. is the classification weight. can be the sigmoid function. represents the predicted probability of node . Therefore, the first half of the equation would contribute to the loss function, if the label is positive (). Otherwise, the second half of the equation would contribute to the loss function.
We can also train the model in an unsupervised manner by using: random walk, graph factorization, node proximity, etc.
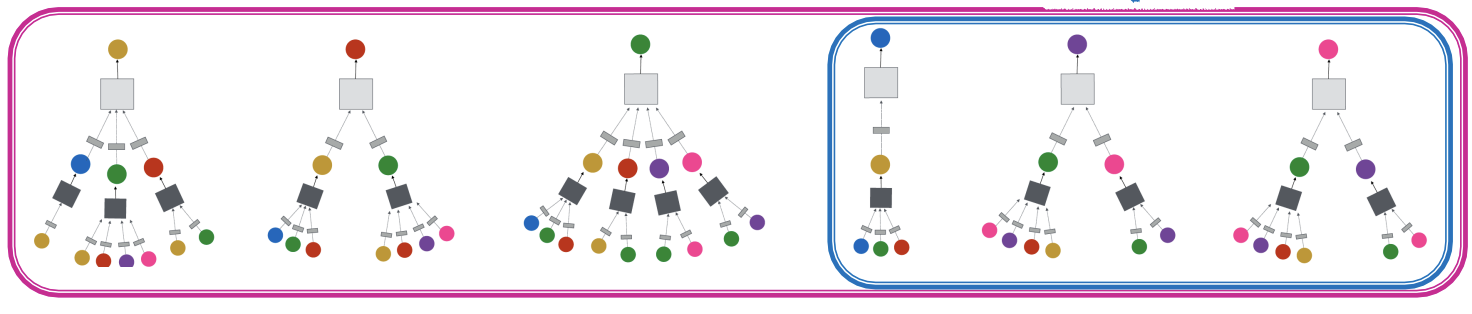
Inductive Capability
GCN can be generalized to unseen nodes in a graph. For example, if a model is trained using nodes , the newly added nodes can also be evaluated since the parameters are shared across all nodes.
GraphSAGE
So far we have explored a simple neighborhood aggregation method, but we can also generalize the aggregation method in the following form:
For node , we can apply different aggregation methods () to its neighbors and concatenate the features with itself.
Here are some commonly used aggregation functions:
- Mean: Take a weighted average of its neighbors.
- Pooling: Transform neighbor vectors and apply symmetric vector function ( can be element-wise mean or max).
- LSTM: Apply LSTM to reshuffled neighbors.
Graph Attention Networks
What if some neighboring nodes carry more important information than the others? In this case, we would want to assign different weights to different neighboring nodes by using the attention technique.
Let be the weighting factor (importance) of node ’s message to node . From the average aggregation above, we have defined . However, we can also explicitly define based on the structural property of a graph.
Attention Mechanism
Let be computed as the byproduct of an attention mechanism , which computes the attention coefficients across pairs of nodes based on their messages:
indicates the importance of node ’s message to node . Then, we normalize the coefficients using softmax to compare importance across different neighbors:
Therefore, we have:
This approach is agnostic to the choice of and the parameters of can be trained jointly with .
Reference
Here is a list of useful references:
Tutorials and Overview:
- Relational inductive biases and graph networks (Battaglia et al., 2018)
- Representation learning on graphs: Methods and applications (Hamilton et al., 2017)
Attention-based Neighborhood Aggregation:
Embedding the Entire Graphs:
- Graph neural nets with edge embeddings (Battaglia et al., 2016; Gilmer et. al., 2017)
- Embedding entire graphs (Duvenaud et al., 2015; Dai et al., 2016; Li et al., 2018) and graph pooling (Ying et al., 2018, Zhang et al., 2018)
- Graph generation and relational inference (You et al., 2018; Kipf et al., 2018)
- How powerful are graph neural networks(Xu et al., 2017)
Embedding Nodes:
- Varying neighborhood: Jumping knowledge networks Xu et al., 2018), GeniePath (Liu et al., 2018
- Position-aware GNN (You et al. 2019)
Spectral Approaches to Graph Neural Networks:
- Spectral graph CNN & ChebNet [Bruna et al., 2015; Defferrard et al., 2016)
- Geometric deep learning (Bronstein et al., 2017; Monti et al., 2017)
Other GNN Techniques: